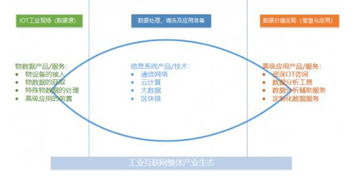
2019年Q3中國(guó)互聯(lián)網(wǎng)文娛市場(chǎng)數(shù)據(jù)發(fā)布報(bào)告解析
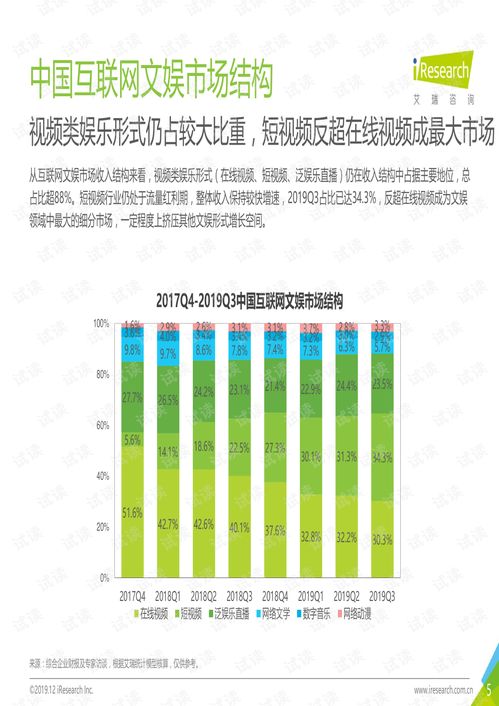
2019年第三季度,中國(guó)互聯(lián)網(wǎng)文娛市場(chǎng)呈現(xiàn)出復(fù)雜而活躍的態(tài)勢(shì)。隨著5G技術(shù)的初步落地和用戶消費(fèi)習(xí)慣的進(jìn)一步演變,文娛產(chǎn)業(yè)在內(nèi)容創(chuàng)新、商業(yè)模式和用戶互動(dòng)等方面均展現(xiàn)出新的特點(diǎn)。本報(bào)告基于互聯(lián)網(wǎng)數(shù)據(jù)服務(wù)提供的最新市場(chǎng)監(jiān)測(cè)與分析,對(duì)當(dāng)季關(guān)鍵動(dòng)態(tài)進(jìn)行梳理與解讀。
核心數(shù)據(jù)概覽顯示,2019年Q3中國(guó)互聯(lián)網(wǎng)文娛整體市場(chǎng)規(guī)模持續(xù)增長(zhǎng),但增速較前幾個(gè)季度略有放緩。短視頻、在線音樂(lè)、網(wǎng)絡(luò)文學(xué)和游戲等細(xì)分領(lǐng)域仍是市場(chǎng)的主要驅(qū)動(dòng)力。其中,短視頻的用戶滲透率和日均使用時(shí)長(zhǎng)繼續(xù)領(lǐng)跑,其商業(yè)化路徑也日益清晰,廣告與電商導(dǎo)流成為重要的收入來(lái)源。
用戶行為方面,報(bào)告指出,Z世代(95后及00后)已成為文娛消費(fèi)的絕對(duì)主力。他們對(duì)內(nèi)容的個(gè)性化、互動(dòng)性和社交屬性要求更高,推動(dòng)了直播互動(dòng)、粉絲經(jīng)濟(jì)、內(nèi)容共創(chuàng)等模式的深化。一線城市市場(chǎng)趨于飽和,下沉市場(chǎng)的用戶增長(zhǎng)和活躍度提升成為行業(yè)新的增長(zhǎng)點(diǎn),平臺(tái)紛紛推出針對(duì)性內(nèi)容和運(yùn)營(yíng)策略以搶占先機(jī)。
內(nèi)容生態(tài)上,IP(知識(shí)產(chǎn)權(quán))的多元化開發(fā)與運(yùn)營(yíng)成為關(guān)鍵。熱門網(wǎng)絡(luò)文學(xué)、動(dòng)漫、影視劇之間的聯(lián)動(dòng)更加頻繁,形成了“一源多用”的跨媒體內(nèi)容矩陣。監(jiān)管政策的持續(xù)完善對(duì)內(nèi)容質(zhì)量提出了更高要求,合規(guī)與創(chuàng)新之間的平衡成為平臺(tái)運(yùn)營(yíng)的重要課題。
從商業(yè)模式觀察,付費(fèi)訂閱和會(huì)員服務(wù)收入占比穩(wěn)步提升,用戶為優(yōu)質(zhì)內(nèi)容付費(fèi)的意愿增強(qiáng)。但與此免費(fèi)增值模式(Freemium)依然占據(jù)重要地位,如何通過(guò)精細(xì)化運(yùn)營(yíng)提升免費(fèi)用戶的轉(zhuǎn)化率,是各平臺(tái)面臨的共同挑戰(zhàn)。廣告收入雖然仍是重要組成部分,但其形式正從硬廣向原生廣告、內(nèi)容營(yíng)銷等更軟性的方式轉(zhuǎn)變。
技術(shù)驅(qū)動(dòng)層面,人工智能和大數(shù)據(jù)在內(nèi)容推薦、用戶畫像分析、版權(quán)保護(hù)等方面的應(yīng)用更加深入。2019年Q3,多家平臺(tái)推出了基于AI的個(gè)性化內(nèi)容生成或交互功能,試圖提升用戶體驗(yàn)和粘性。5G網(wǎng)絡(luò)的建設(shè)進(jìn)度也為未來(lái)的超高清視頻、云游戲、VR/AR等沉浸式文娛應(yīng)用鋪墊了基礎(chǔ),雖然當(dāng)時(shí)仍處于早期階段,但已引發(fā)行業(yè)廣泛布局。
競(jìng)爭(zhēng)格局方面,市場(chǎng)頭部效應(yīng)依然明顯,騰訊、字節(jié)跳動(dòng)、阿里巴巴、百度等巨頭通過(guò)投資、自建和戰(zhàn)略合作,持續(xù)鞏固其在文娛各細(xì)分領(lǐng)域的地位。但垂直細(xì)分領(lǐng)域的創(chuàng)新企業(yè)不斷涌現(xiàn),憑借獨(dú)特的內(nèi)容或社區(qū)運(yùn)營(yíng),在特定用戶群中建立起競(jìng)爭(zhēng)力。
挑戰(zhàn)與展望部分,報(bào)告了當(dāng)季市場(chǎng)面臨的主要問(wèn)題:包括內(nèi)容同質(zhì)化競(jìng)爭(zhēng)加劇、用戶獲取成本上升、數(shù)據(jù)隱私與安全監(jiān)管趨嚴(yán)等。報(bào)告預(yù)測(cè),隨著技術(shù)迭代和消費(fèi)升級(jí),中國(guó)互聯(lián)網(wǎng)文娛市場(chǎng)將繼續(xù)向精品化、智能化、生態(tài)化方向發(fā)展。深耕垂直領(lǐng)域、強(qiáng)化技術(shù)賦能、拓展海外市場(chǎng),以及探索更多元可持續(xù)的盈利模式,將成為企業(yè)突圍的關(guān)鍵。
本報(bào)告基于詳實(shí)的互聯(lián)網(wǎng)數(shù)據(jù)服務(wù),旨在為行業(yè)參與者、投資者及觀察者提供客觀的季度市場(chǎng)洞察,助力把握趨勢(shì),驅(qū)動(dòng)決策。數(shù)據(jù)背后,是中國(guó)互聯(lián)網(wǎng)文娛產(chǎn)業(yè)在創(chuàng)新與規(guī)范中不斷前行的生動(dòng)寫照。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://m.go2dg.cn/product/34.html
更新時(shí)間:2026-06-19 09:57:08