互聯網技術詳解 大型數據中心網絡路由設計與優化(一)—— 互聯網數據服務的基石
在當今數字化浪潮中,大型數據中心已成為支撐全球信息流動、云端服務與社會運轉的核心引擎。無論是我們日常使用的社交媒體、流媒體視頻,還是企業級的云計算、人工智能訓練,其背后都依賴于龐大、復雜且高效的數據中心網絡。本系列文章將深入探討大型數據中心網絡的核心——路由設計與優化。作為開篇,我們首先需要理解現代互聯網數據服務對底層網絡提出的根本性要求。
一、現代互聯網數據服務的特征與挑戰
現代互聯網數據服務呈現出幾個鮮明的特征,這些特征直接決定了數據中心網絡架構與路由設計的走向:
- 東西向流量主導:傳統企業網絡流量模式以“南北向”(用戶到數據中心服務器)為主。而在數據中心內部,特別是在進行分布式計算、存儲同步、微服務間通信時,服務器與服務器之間產生的“東西向”流量占據了絕對主導地位,可高達總流量的70%-80%。這就要求網絡必須具備極高的橫向(機架間)帶寬和超低的延遲。
- 海量并發與突發性:一項服務可能瞬間被全球數百萬用戶訪問,同時內部的數據備份、MapReduce作業等也會產生突發的大數據流。網絡必須具備彈性伸縮和應對“大象流”(大規模長時數據流)與“老鼠流”(大量短時小數據流)混合負載的能力。
- 租戶隔離與多業務承載:一個物理數據中心需要同時為成千上萬個不同客戶(租戶)或內部不同業務部門提供服務。網絡必須在共享的物理基礎設施上,實現嚴格的流量隔離、安全邊界和差異化的服務質量(QoS)保證。
- 高可用性與快速故障恢復:服務中斷的代價極其高昂。網絡設計必須追求“五個九”(99.999%)甚至更高的可用性,這意味著需要從設備、鏈路、協議各個層面實現冗余,并能在毫秒級內檢測并繞開故障點。
- 可擴展性與成本效率:數據中心規模持續增長,從數千臺服務器擴展到數十萬乃至百萬臺。網絡架構必須能夠平滑、線性地擴展,同時控制布線復雜度、設備成本和能源消耗。
二、數據中心網絡路由設計的基礎目標
基于上述服務需求,數據中心網絡的路由設計圍繞幾個核心目標展開:
- 無阻塞高帶寬:通過CLOS等多級交換架構,提供非 oversubscription(無超額訂閱)或低超額訂閱的帶寬,確保任意兩臺服務器間都有充足的路徑帶寬。
- 低延遲與可預測性:路由協議和轉發機制需要盡可能減少處理時延和排隊時延,尤其對于金融交易、實時交互類應用,延遲的穩定性(抖動小)與絕對值同樣重要。
- 高利用率與負載均衡:避免出現部分鏈路擁塞而部分鏈路閑置的情況。需要動態、高效地將流量均勻分布到所有可用的路徑上,最大化網絡基礎設施的投資回報。
- 簡化運維與自動化:面對龐大的規模,手動配置和管理不可行。路由設計需與SDN(軟件定義網絡)理念結合,實現集中控制、策略下發和自動化的故障響應與擴容。
三、經典架構與路由演進概述
早期數據中心普遍采用傳統的三層樹形架構(接入-匯聚-核心),其路由依賴生成樹協議(STP)來避免環路,但這會導致大量鏈路被阻塞,帶寬利用率低下,且收斂速度慢。
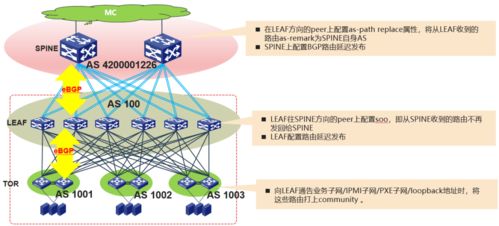
為應對東西向流量挑戰,CLOS架構(或稱葉脊架構)已成為現代大型數據中心的主流選擇。在該架構中,每一個葉交換機(連接服務器)都與每一個脊交換機相連,形成了豐富的等代價路徑。這自然地將網絡路由設計的焦點從“避免環路”轉向了“多路徑利用”。
在此物理基礎上,路由協議也隨之演進:
- 二層路由的演進:從STP到TRILL、SPB等技術,試圖在二層實現多路徑轉發。
- 三層路由的普及:直接在葉和脊交換機間運行三層路由協議(如OSPF、BGP),將整個數據中心變成一個大的IP網絡,利用ECMP(等價多路徑路由)來實現流量的負載分擔。這種方式簡化了網絡,消除了大二層域帶來的廣播風暴風險,是目前最主流的方案。
- SDN與集中式控制:通過如BGP-SDN、P4等技術與協議,將控制平面集中,由控制器全局計算最優路徑并下發流表,實現更精細、靈活的流量調度和策略實施。
###
互聯網數據服務的需求是數據中心網絡演進的原始驅動力。從以南北流量為主的樹形結構,到為東西流量而生的葉脊架構,網絡路由設計的核心思想已從“連通與防環”進化為“高效與智能”。理解了這一背景和基礎目標后,我們將在后續篇章中,深入解析ECMP的具體實現、負載均衡算法、在CLOS架構中BGP的應用細節、以及SDN如何進一步優化流量工程等關鍵技術,揭開大型數據中心網絡高效運轉的神秘面紗。
如若轉載,請注明出處:http://m.go2dg.cn/product/45.html
更新時間:2026-06-19 12:00:05